Written by Philip Howard (Bloor Software Analyst)
Philip’s a Bloor Software Analyst who started in the computer industry way back in 1973. He worked as a systems analyst, programmer and salesperson, as well as in marketing and product management roles, for a variety of companies including GEC Marconi, GPT, Philips Data Systems, Raytheon and NCR. More about Bloor...
There are various definitions of what a CDO is and does but the Wikipedia definition is reasonably consensual. It states that “a chief data officer (CDO) is a corporate officer responsible for enterprise wide governance and utilization of information as an asset, via data processing, analysis, data mining, information trading and other means”. It goes on to say that, “the Chief Data Officer has a significant measure of business responsibility for determining what kinds of information the enterprise will choose to capture, retain and exploit and for what purposes.”
Not all organisations seem to understand the “chief” part of this definition. We know of some companies that have “upgraded” their data stewards into CDOs. No doubt the title change makes their staff feel better about themselves but Departmental Data Officer might be a more appropriate name in these circumstances. To be clear, we are discussing the role of CDO as a function that spans operational and departmental silos. This is important to appreciate because silos of data are part and parcel of the problems that CDOs have to face. In other words, the CDO really is a “chief”.
More generally, what is the function of the Chief Data Officer (CDO)? In particular, what are the issues and problems that face a CDO, and which a CDO should be able to resolve, that are not within the compass of a CIO? In effect, why do you need a CDO? When do you need a CDO? What makes a CDO different? One set of answers to that is the business responsibility mentioned in the Wikipedia description, and the whole question of what data is required and how it should be exploited. That is not what we will discuss in this paper. Here we are going to consider more fundamental issues. Before a CDO can think sensibly about what data the business might want to leverage, whether now or in the future, he or she is going to have to get a handle on the data assets that the company already possesses. In particular, these need to be discovered, understood, governed and secured, all of which are exacerbated by the scale and, especially, by the complexity of your data landscape.
Finally, notice that that there is an overlap between the business role of the CDO and other officers such as the Chief Privacy Officer. In particular, the exploitation of (sensitive) data impinges directly on the latter and may require the imposition of additional controls to mitigate potential privacy issues.
Complexity is both a business issue and a data issue and each reflects the other. According to Mocker et al (Mocker, Weill and Woerner: “Revisiting Complexity in the Digital Age” MIT Sloan Management Review, June 2014) “as businesses entered new geographies, developed new products, opened new channels and added more granular customer segments, they made their offerings more complex with the intention of adding value. But, as an almost inevitable consequence, companies also made it more difficult for customers to interact with the company and more unwieldy for employees to get things done”. Conversely, they go on to argue that “with today’s increased digitization, companies can finesse this trade-off (between complexity’s costs and benefits) and can increase value-adding complexity in their product offerings while keeping processes for customers and employees simple. Our research suggests that companies operating in this ‘complexity sweet spot’ outperform their competitors on profitability”.
Mocker and his associates define business complexity as the amount of variety and links that exist within the company in question, where variety is the difference in one or more important characteristics, and links are connections or dependencies. If we think in terms of products, variety would represent the different models and options associated with each product, while links and dependencies might relate to delivery options, parts assemblies, related suppliers, service contracts and so on.
And this is where we come to data complexity because you cannot hide business complexity unless you understand all the varieties, links and dependencies that exist. Further, some variation necessarily drives complexity while other variations may do so only accidentally. In theory, you would like to simplify your environment in the second case but that requires understanding not just the complexity itself but also from where it derives. Exploring these data-driven issues is non-trivial but can be done using cluster analysis that illustrates commonality across data models and highlights where there are variations. An example of the visualisation of this is shown later in this paper (Figure 3). While it does not explain the differences between the data models shown it does illustrate where they exist so that variations can be explored in more detail.
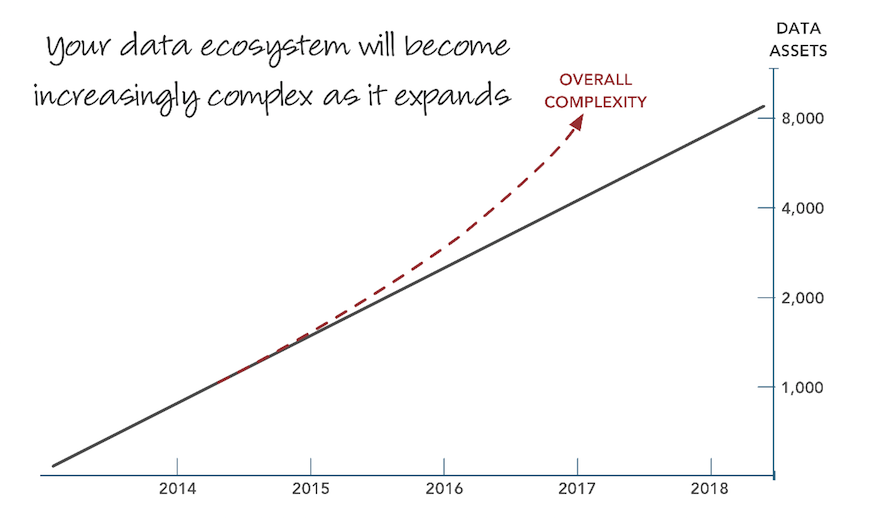
"The problem with data is that it is growing. And growth implies complexity. And as data gets more and more complex it becomes more dif cult to understand and that in turn means that the governance and security of that data is increasingly an issue."
The problem with data is that it is growing. And growth implies complexity – see Figure 1. And as data gets more and more complex it becomes more difficult to understand and that in turn means that the governance and security of that data is increasingly an issue. Nor are we just talking about future problems. There are companies today that have environments with hundreds, thousands or even tens of thousands of databases. Typically, the CDO will not know exactly (or even approximately) how many database instances there are, how many are production versus non-production (for development, testing and so forth) databases. Moreover, the CDO will not know how many and which databases store, for example, customer data; and whether or not that data is duplicate data or about different or overlapping customer data sets. Further, there are probably databases that have redundant, trivial or out-of-date information within them. Worse, the CDO will not know which data is sensitive or subject to data protection regulations and the discovery and classification of this data is likely – assuming that the CDO wants to stay out of jail – to be a priority, so that appropriate controls can built around this data.
In such an ecosystem there are a lot of things that you can’t do. You can’t effectively rationalise or simplify your environment: if you don’t know where you are starting from then you are more likely to make things worse than better. In other words, you cannot solve business complexity if you cannot resolve data complexity. Further, you can’t efficiently apply policies – of various types – across your ecosphere, if you don’t understand its landscape in the first place. For example, data governance and data quality initiatives need to encompass all relevant data and you can’t do that if you don’t know where it all is. Data privacy concerns apply similarly: you need to ensure that sensitive data is masked or obscured wherever that data resides, and the same also applies if you are applying any sort of data-centric security.
In addition to these largely technical considerations (although rationalisation has obvious cost saving implications) there are direct business related issues that derive from a lack of ecosystem understanding. At a more detailed level that “business complexity”, the most obvious is that if you don’t know, or can’t easily find out, where all of your customer data is, then you cannot analyse that data efficiently. This will result in inaccurate customer churn predictions, next best offers that actually aren’t, and generally a skewed perspective on the business. Similarly, if you are a bank or other financial institution, then how can you calculate systemic risk if you don’t know where all of your data is or how it is interconnected?
Note that although we have focused on large environments all of these discussion points are true of any organisation, even where the environment is relatively simple. As Figure 1 indicates, as your business grows, as you leverage more and more information, your data environment will become more complex: better to gain an understanding now and let that understanding grow alongside your business growth.
How does a newly appointed CDO go about tackling the discovery and understanding of the organisation’s data assets? Logically, there are four basic steps to go through, which we will discuss in turn.
Of course, none of these is a trivial task but each of these needs to be completed before you can implement enterprise-wide data governance and security measures. Note that “enterprise-wide” is an important consideration here: we are not talking about siloed deployment of data quality solutions, for example, but data quality applied across all relevant data. A further point is that, although we are focusing here on what the CDO needs to understand from an initial perspective, this is not a static process. Databases get new capabilities and new databases get spun up on a regular basis so the discovery, profiling and other tasks that we discuss here need to be rerun and updated on a regular basis.
The first step in discovery and understanding comprises of what Bloor Research calls data cataloguing. Some vendors referred to this as data discovery but this is a term also used by business intelligence vendors and is, therefore, potentially confusing. Firstly, you are discovering all of your data sources (crawling across your corporate intranet and discovering appropriate extension names) and, secondly, you are collecting whatever metadata you can about those data sources. Needless to say, this may need to be augmented subsequently by manual methods – it may not, for example, be immediately obvious who owns this particular database – but, in so far as is possible, this process should be fully automated. What emerges is a catalogue that contains the metadata that describes all of your sources. This catalogue will be augmented further as you go through additional discovery phases and you would expect search and associated features to run against the catalogue so that you can explore it in detail. Note that there are a number of tools in the market that do this cataloguing specifically for data lakes (prior to performing analytics) but we are talking here about a wider capability that is more generic.
Once you know where your data sources are located, and you know something about them, you will want to know about the data in each source. This applies at two levels. Firstly, you will want to know what sort of data this is: is it customer data, supplier data, employee data, or financial data? Given that you want to discover this automatically – if you have thousands or tens of thousands of data sources this is imperative – then the software tools you are using will need to have some semantic awareness to recognise the different terminologies in use. For example, database records for suppliers and customers – especially where these are business customers – look very alike, and you need to be able to distinguish between them. This domain profiling may go deeper: for example, suppose that you supply both doctors and dentists, then you might like to distinguish between these customer classes. A knowledge of relevant ontologies would help you to do that.
Not only do you want this sort of high level profiling you will need to profile the table and column also. This is for three reasons. Firstly, it is necessary in order to support the domain profiling just described. Secondly, it is a pre-cursor to the data governance we will discuss later and, thirdly, it is necessary in order to discover relationships that exist between data elements both within and across data sources.
Once you understand the content of your different data sources you can start to infer relationships (or links in business complexity terms) between these sources. In practice, there are a variety of different types of relationship that might exist. For example, for testing and development you might have a) a copy (or copies) of your production database, b) a sampled version (or versions) of your production database or c) a synthetically generated version (or versions) of your production database. Complete or sampled copies of the database may or may not be masked (or, perhaps, should be masked or encrypted but aren’t), depending on the content, and they may or may not be virtual rather than physical copies. Each of these has a slightly different relationship to the original database, which need to be captured. The same applies to copies of the database retained for back-up and recovery or for other purposes.
Relationships do not only apply at the database level – as illustrated in Figure 2 – but also at the domain, table, column and even individual data element level. For example, it is entirely possible to conceive of the same customer appearing in two different data sources but where the actual content of the relevant dataset – apart from the customer details themselves – are totally distinct. Some semantic capabilities will be needed at this level if relationships are to be discovered automatically: for example, recognising that “Cust_ID” is the same as “CustNo”. Unfortunately, while this will help, you will never get full automation in this respect until and if organisations adopt and implement formal policies on naming conventions for tables and columns of data. In practice these often resemble gobbledigook and although domain profiling (with ontological support) may help, there is always likely to be some manual intervention required.
A further consideration is that there is a distinction between physical and logical relationships. In the former case it may be that data is replicated from one database to another, or it is physically moved using ETL (extract, transform and load) or similar processes. On the other hand, two distinct databases that are not physically linked may have logical relationships between them if, say, they both contain product data.
"Once you understand the content of your different data sources you can start to infer relationships between these sources."
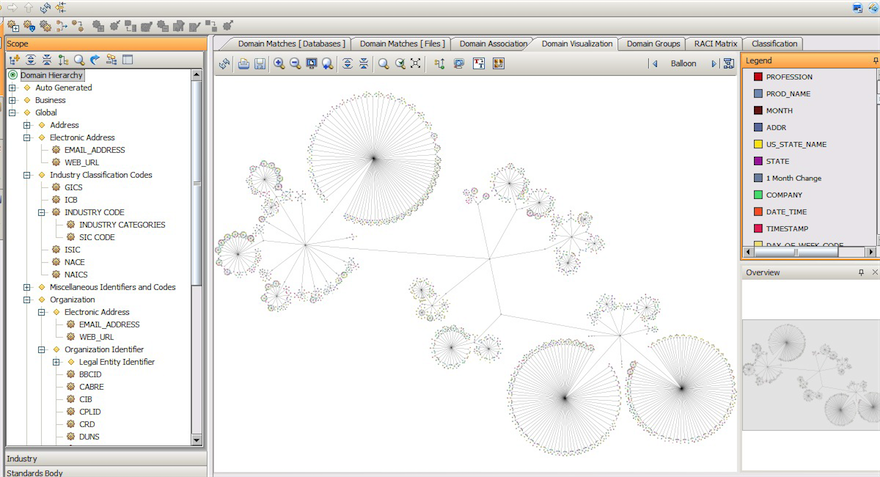
All of these relationships can be inferred from the domain and data profiling already performed, along with some additional capabilities such as the ability to infer relationships based on time stamps (if x and y consistently happen at the same time then x and y are probably linked in some way). However, actually exploring these relationships is not trivial in large and complex environments and it will be best if such relationships can be explored graphically, as illustrated in Figure 3, which shows domain profiling.
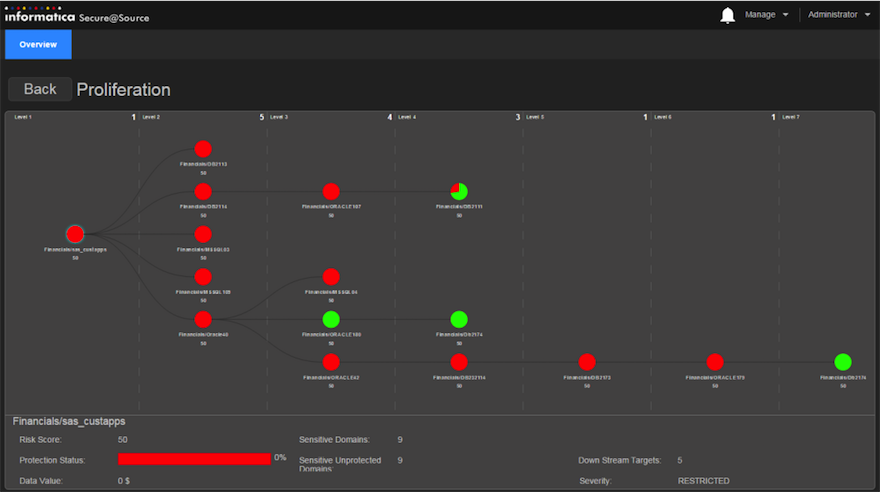
Once you understand the physical relationships that connect data sources you can derive data lineage that shows how data moves through the data landscape of the company and how it is transformed, protected and secured (or not) along the way. This is important for a number of reasons. Firstly, data lineage needs to comply with Sarbanes-Oxley and other compliance initiatives. Secondly, in the case of spreadsheets one of the biggest causes of failures and errors is broken links and the landscape discovery process should expose these. Thirdly, you can track how data governance and security procedures are applied to the data. For example, Figure 4 illustrates data lineage as data moves through the organisation, monitoring where relevant data has been masked or obfuscated: red dots show a lack of masking, green dots indicate where this has been done appropriately. Similar issues arise with data quality: what you want to do is to ensure the quality of data at the first point in the lineage rather than somewhere down the line.
Generally speaking, data lineage is row-based but in analytic environments it may be important on a columnar basis as well. However, this is not a foundation issue for the CDO and can be left to more user-facing tools within the analytic environment.
We left the catalogue with details about your data sources per se, but not much else. In practice, the catalogue should be updated and extended with all of the information derived from data and domain profiling, the information we have inferred through semantic analysis and about relationships and data lineage. Further, you should be able to query or, more particularly, search the catalogue. In addition, it will be useful for users not only to know where data is and where it comes from and goes to, but also what it means and how it is derived. In other words, a business glossary should be associated with or built into the catalogue. This should provide both business and technical definitions of terms as well as their derivations. Note that derivations – for example, how monthly profit is calculated – can be deduced from the data lineage.
So far we have discussed the discovery and understanding of data assets. You may think that is a worthwhile exercise in its own right but here we want to discuss how that understanding can be leveraged and there are a variety of potential uses cases – governance, rationalisation, security and analytics are just four – that we will consider in turn.
In a large data ecosphere three things are likely. Firstly, you are redundantly storing data. That is, you have multiple copies of the same data, not all of which are required. Secondly, you have out-of-date data that is not required for archiving purposes and that is not being accessed. And, thirdly, you are storing trivial information that you don’t need and isn’t relevant. The acronym for this sort of data is, appropriately, ROT (redundant, out-of-date or trivial). For obvious reasons you would like to rationalize your systems so that you no longer store this data. But, of course, you cannot do this unless you first have a comprehensive understanding of your data landscape. However, CDOs need to bear in mind that what may seem dross to one person may have great value to another. This is one reason to establish who owns and accesses the data you have discovered.
Surveys suggest that one in three executives don’t trust the data upon which their company’s business intelligence and analytics processes are based. There are a variety of reasons why this might be the case. The first is that the data that needs rationalising and that analyses are including duplicated or out-of-date data that is skewing results. Secondly, not all information is being included in reports and analyses. This is because data is dispersed across the organisation and nobody knows where it all is and how to pull it together which, of course, is the major topic behind this paper. And, thirdly, users don’t trust the quality of their data. We will discuss this in the next section.
Endless papers have been written, by Bloor Research and others, into the importance of data quality, not just in conventional environments but for big data and the Internet of Things also. We will not go over those arguments again. However, these papers tend to focus on data quality per se. Moreover, data quality vendors have tended to adopt a “land and expand” sales model, which has led to islands of good data quality within organisations so that data, for a quality and governance perspective, exists in a series of silos. This is, frankly, not good enough. If those silos consisted of complete domains – all customer data, for example, or all product data – then the environment might be acceptable. However, data quality tends to be siloed by department. So the sales department may have good quality customer data but the service and maintenance department doesn’t. Needless to say, enterprise-scale data quality needs to ensure that all customer data, wherever it resides, is of suitable quality. One of the first tasks of the CDO, therefore, after the discovery and understanding of data, is to identify whether it is quality controlled or not, and to implement appropriate processes where that is not the case.
Data protection is subject to geo-political issues. For example, the EU has recently passed the General Data Protection Regulation (GDPR), which means that all organisations above a certain size will be required to appoint a Data Protection Officer (DPO). This raises the question of whether the DPO is independent of the CDO or reports to the CDO. We imagine the latter. The fundamental point behind GDPR is that information about a customer belongs to that customer and does not belong to the company that has gathered that information. As such the customer has rights as to how his or her information may be used. First of all, that implies that you will have to know every location where customer data resides – which we have been discussing here all along – but you will also need the ability to append appropriate flags to this data at the row level, indicating how you are allowed to use the data.
Leaving consideration of GDPR aside, the primary functions required here are to identify sensitive data and then to take appropriate steps to protect that data. The former, again, requires understanding where all your data is, and then use profiling and other (semantic) mechanisms to determine if any particular piece of data is sensitive. It would be good practice, once sensitive data has been discovered, to also trace its lineage (both forward and backward) as a double check that you have found all instances of the data. The data can then be masked or obfuscated in an appropriate manner. The ability to visualise what we might call masking lineage, will be useful for auditing and compliance purposes, in order to prove that all instances of sensitive data have been appropriately secured. For data in-flight, as opposed to data at rest, you may need to employ dynamic data masking, tokenisation or encryption, depending on the circumstances. For test data you may choose to use synthetic data that does not require masking.
Returning to the geo-political point raised at the beginning of this section, there are issues over privacy when data is moved from one jurisdiction to another. In some cases, this is expressly forbidden, in others it may require specific permission, while in yet more cases there may be no problem. These concerns need to be mapped to the data landscape. Further, data lineage will need to be used to track the provenance of data and to ensure that privacy regulations are not breached.
The role of the CDO extends beyond the details that we have discussed in this paper. However, we believe that unless the CDO tackles the fundamental issues that we have highlighted, then all the other tasks that face the CDO will be impossible or, at least, any results will be dysfunctional. In other words, discovering and understanding your data landscape is a necessary condition for meeting the functional requirements of a CDO, even if it is not, on its own, sufficient.

This spotlight report was brought to you in partnership with the software analyst firm Bloor. Click here for more information on Bloor, here for more content from Crozdesk and here to start a software search.