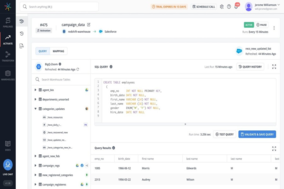
Hevo Data is a no-code, bi-directional data pipeline platform specially built for modern ETL, ELT, and Reverse ETL Needs. It helps data teams streamline and automate org-wide data flows that result in a saving of ~10 hours of engineering time/week and 10x faster reporting, analytics, and decision making.
The platform supports 100+ ready-to-use integrations across Databases, SaaS Applications, Cloud Storage, SDKs, and Streaming Services. Over 500 data-driven companies spread across 35+ countries trust Hevo for their data integration needs. Try Hevo today and get your fully managed data pipelines up and running in just a few minutes.
About MapR
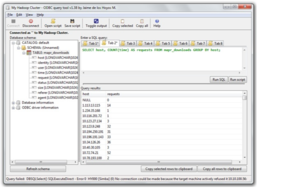
MapR offers one of industry’s leading unified data platforms that is capable of performing analytics and applications with speed, scale, and reliability. Companies that use this solution are able to to do analytics and applications simultaneously as data happens.
MapR provides access to a diversity of data sources including Apache Hadoop, Apache Spark, a distributed file system, a multi-model database management system, and event stream processing. The platform features high performance, simple deployment and TCO through its converged platform. Its NFS function allows users to copy to an NFS share that is distributed across the entire cluster.
Besides MapR Converged Data Platform, MapR offers following modules: MapR-XD, highly-scalable storage module; MapR Analytics and ML engines, for real-time analytics; MapR-DB, which is a high-performance NoSQL database; MapR-ES, the event streaming system for big data; The MapR Control System, for administering the MapR Converged Data Platform; MapR-Edge, for capturing, processing, and analyzing IoT data.
About Panoply
With click and collect functionality for any type of data, from structured to semi-structured, Panoply can gather data from your favorite SaaS API, any database, file store, or even flat files. No coding or engineering knowledge is required. You simply connect to your data source and click one button to start collecting data. As we gather your data we automatically build your data model. As you grow Panoply’s elastic warehouse scales and optimizes with your data. You can schedule your data to refresh as often as you need. As new data is collected Panoply automatically adjusts the data model and scales infrastructure for maximum performance.
Features
2-Factor Authentication
A/B Testing
Analytics
API
Calendar Management
Contact Management
Dashboard
Data Export
Data Import
Data Mining
Data Visualization
External Integrations
Forecasting
Keyword Tracking
Multi-User
Notifications
Scheduling
SEO
Features
2-Factor Authentication
A/B Testing
Analytics
API
Calendar Management
Contact Management
Dashboard
Data Export
Data Import
Data Mining
Data Visualization
External Integrations
Forecasting
Keyword Tracking
Multi-User
Notifications
Scheduling
SEO
Features
2-Factor Authentication
A/B Testing
Analytics
API
Calendar Management
Contact Management
Dashboard
Data Export
Data Import
Data Mining
Data Visualization
External Integrations
Forecasting
Keyword Tracking
Multi-User
Notifications
Scheduling
SEO
Summary
Pre-built Integrations with 100+ Data Sources
Fully Automated Data Flows with No-code Interface
Supports ETL, ELT, and Reverse-ETL use cases
Data Modeling and Workflows
Real-time Alerts & Notifications
Replay/Re-run Failed Events
Auto-schema Management
Supports Historical and Incremental Data Load (CDC)
Secure Connection with SSH Tunnel and SSL/TSL Encryption
Supports Advanced Transformations
Summary
Apache Hadoop
MapR-DB
Scalability
Standards-Based APIs and Tools
Manageability
Direct Access NFS™
Integrated Security
Multi-Tenancy
Consistent Snapshots
High Availability
Summary
Instantly ingest ANY data source with Built-in ETL
Standard SQL bench for querying directly in the data warehouse
Seamlessly connect to ANY BI visualization tool of your choice
Data modeled automatically thanks to natural language processesing
Built-n scalability and storage optimization thanks to machine learning
Automated performance optimization of storage and queries for a superior concurrency experience
Pricing
Free Plan
Free
Included in plan:
Includes 1 Million Events
Starter Plan
$149.00
1 user(s) / month
Included in plan:
Includes 10 Million Events
Business
1 user(s) / month
Included in plan:
Includes Custom Number of Events
Pricing
Starter
$249.00
company license
Included in plan:
25 million rows
up to 12.5 GB of Storage
Unlimited Queries
PRO
$499.00
company license
Included in plan:
100 million rows
up to 50 GB of Storage
Unlimited Queries
Business
$749.00
company license
Included in plan:
Dedicated Data Architect
200 million rows
up to 100 GB of Storage
Unlimited Queries
Custom - enterpise
Custom Enterprise license
Included in plan:
Any # of Sources
Any # of Rows
Elastic Storage
Unlimited Queries
Dedicated Data Architect
FAQs
Who are the main user groups of this service?
Data Engineers, Data Scientist, Business Analyst, Data Analyst, BI Engineers
Does this service offer guides, tutorials and or customer support?
Yes
Does this service offer multi-user capability (e.g. teams)?
Yes
Does this service integrate with any other apps?
Yes
What is this service generally used for?
ETL, Data Migration, Data Warehousing
Does this service offer an API?
Yes
FAQs
What are some applications this service is commonly used in tandem with?
It is commonly used in tandem with various databases.
Who are the main user groups of this service?
Users of MapR are SMEs and large enterprises in Telecommunications, Healthcare, Financial Services, Retail, Media and Entertainment, Manufacturing, Oil and Gas, and Public Sector.
What platforms does this service support?
Users of MapR can choose the hardware, hypervisor, container and cloud platform that best suits their business. They will be able to move exabytes of data across edge, on-premises, and cloud deployments, as well as to automate data transfer across storage tiers, including SSD, HDD, and cloud.
Does this service offer an API?
Yes.
Does this service offer multi-user capability (e.g. teams)?
No.
What is this service generally used for?
This service is generally used for big data management.
Does this service offer guides, tutorials and or customer support?
Does this service offer guides, tutorials and or customer support?
Yes, we have or online resources, including documentation, demos/tutorial vids, Community Forum of friendly users, live chat (not a bot! ) and our expert Data Architects who are on-call and always ready to help our customers or prospective customers.
Does this service offer an API?
We have an SDK.
Does this service offer multi-user capability (e.g. teams)?
Yes, we support teams with specific permission controls.
Who are the main user groups of this service?
Business analysts, data analysts, data engineers, and data scientists. Essentially, anyone working with analytics can easily use Panoply to gather any data sources and seamlessly connect to any BI visualization tool without being tech savvy or needing IT and engineering help to do so.
Does this service integrate with any other apps?
Yes, more than 150 apps, services & APIs. Panoply can seamlessly ingest any data source with its built-in ETL and instantly render the data to be ready to be queried - no coding or data engineering required.
What platforms does this service support?
We have over 150 integrations with databases, APIs, web apps and more. Go to the Panoply.io integrations page to see all of our integration partners.
What are some applications this service is commonly used in tandem with?
Chartio, Looker, Tableau, PowerBI and any standard SQL Workbench; R and python.
What is this service generally used for?
For citizen analysts that are dissatisfied with IT limiting their ability to provide data-driven insights, Panoply is a self-serve smart cloud data warehouse that automates and simplifies the data stack. Unlike in-house IT, we have assembled a "data team in a box" that empowers analysts to push a button and get a data warehouse up and running in minutes, not days.

 view 5 more
view 5 more
 view 4 more
view 4 more
